Mais combien y a-t-il de femmes scientifiques sur Wikipédia ? (this time with SPARQL)
Dans mon dernier billet, j’explorais les possibilités d’exploiter les données de Wikidata avec Autolist. Il est maintenant possible d’interroger Wikidata en utilisant le langage standard du web sémantique, SPARQL. Je ne vais pas faire un cours de SPARQL sur ce blog, mais je vais détailler une requête étape par étapes.
Comme c’est à nouveau le jour de l’éditathon Femmes de sciences, je vais reprendre la même requête que la dernière fois : combien y-a-t-il de femmes scientifiques sur les projets Wikimedia, et quel taux par rapport aux hommes ?
Pour commencer, ça se passe par là : https://query.wikidata.org/
Et comme première requête, on va demander de lister 10 êtres humains, sans préoccupation de genre ou de profession. Cela se formule comme ça :
PREFIX wd: <http://www.wikidata.org/entity/> PREFIX wdt: <http://www.wikidata.org/prop/direct/> select distinct ?personne where { ?personne wdt:P31 wd:Q5 . } LIMIT 10
Les deux préfixes au début permettent d’éviter d’avoir à taper en entier les URL des ontologies qu’on utilise. On en ajoutera au fur et à mesure qu’on en aura besoin. Vous pouvez cliquer sur le bouton « Add prefixes » pour en ajouter un paquet d’un coup mais pour les besoins de ce tutorial, je ne vais inclure dans chaque requête que ceux qu’on utilise vraiment.
passons à la requête elle-même :
select distinct ?personne
Ceux pour qui le langage SQL est familier ne seront pas trop dépaysés : « select » est la commande pour demander au serveur de retourner un liste de résultats, « distinct » demande au serveur d’éliminer les doublons éventuels dans les résultats. « ?personne » est une variable qu’on va préciser plus bas, mais remarquez juste pour l’instant que les variables commencent par des points d’interrogation en SPARQL.
On continue avec la clause « where » où on va détailler au serveur ce qu’est cette fameuse variable ?personne qu’on lui demande.
where { ?personne wdt:P31 wd:Q5 . }
Pour rappel, on cherche en fait des éléments Wikidata. Sur Wikidata, un élément est composé de déclarations dont la structure est la suivante :
Capture d'écran d'une déclaration
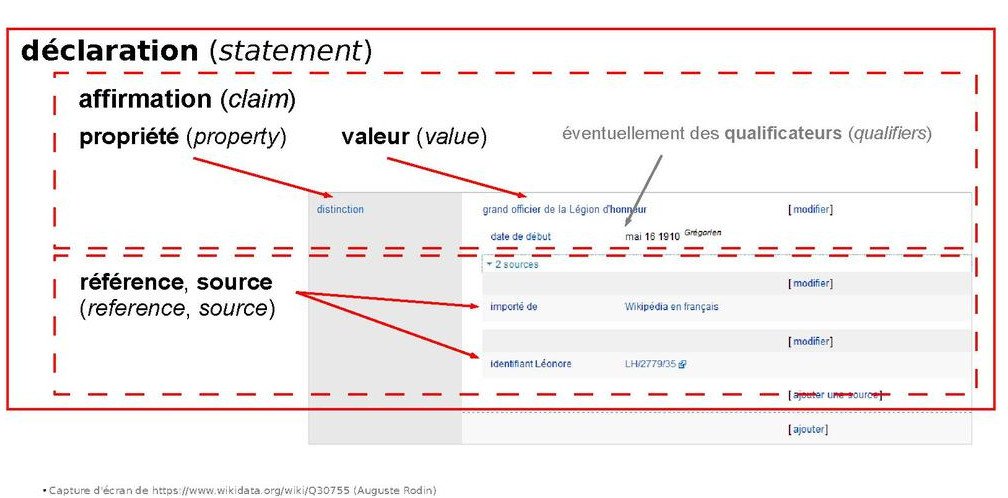
Ici, la structure :
?personne wdt:P31 wd:Q5 .
peut se lire, dans le jargon du web sémantique :
<sujet> <prédicat> <objet> .
ou dans celui de Wikidata :
<élément> <propriété> <valeur> .
Comme ce sont des éléments qu’on cherche, on remplace cette partie par notre variable. La propriété qu’on cherche est P31 (nature de l’élément) et la valeur Q5 (être humain), et pour éviter de mettre les URL en entier on va utiliser les préfixes définis plus haut. On a donc wd: pour un élément wikidata et wdt: pour une propriété.
Enfin, le « LIMIT 10 » permet d’éviter de sortir une liste interminable de résultats qui prendrait un temps fou et dont l’affichage mettrait probablement à mal le navigateur.
Lançons maintenant la requête.

Résultat de la requête
On a bien 10 résultats, mais ce qui serait bien, c’est d’afficher le label à côté, parce que de tête, je ne sais pas qui sont wd:Q260 ou wd:Q272.
PREFIX bd: <http://www.bigdata.com/rdf#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX wd: <http://www.wikidata.org/entity/> PREFIX wdt: <http://www.wikidata.org/prop/direct/> SELECT DISTINCT ?personne ?personneLabel WHERE { ?personne wdt:P31 wd:Q5 . SERVICE wikibase:label { bd:serviceParam wikibase:language "fr,en" . } } LIMIT 10
On ajoute donc un petit bout de code faisant appel au service « label » de Wikibase. C’est quelque chose de spécifique à Wikidata, qui ne correspond pas au standard (qui serait d’appeler la propriété rdfs:label) et est dû au fait que Wikidata a une gestion très poussée des langues. Elle permet cependant de faire un truc sympa : on peut lui préciser un langage de repli s’il n’y a pas de label dans la première langue demandée. Ainsi ici, si un élément remonté n’a pas de label en français, on va se replier sur celui en anglais. Pour ceux n’ayant pas de label dans ces deux langues, c’est l’identifiant Wikidata qui sera affiché.
J’ai ajouté également les préfixes pour les deux nouvelles ontologies utilisées. Enfin, on rajoute la deuxième colonne demandée au select. La syntaxe « ?<variable>Label » est particulière à ce service.
Continuons maintenant à préciser la requête : on se rappelle qu’on veut spécifiquement les femmes scientifiques.
Commençons par le genre.
On veut les personnes qui ont la valeur « femme (Q6581072) » à la propriété « sexe ou genre (P21) », et on a juste à ajouter la ligne
?personne wdt:P21 wd:Q6581072 .
dans notre clause where. Pour la profession, c’est un peu plus compliqué : la plupart des scientifiques ne sont en effet pas recensés en tant que scientifiques directement mais avec des professions plus précises, comme Marie Curie qui est physicienne et chimiste. On veut donc non seulement les gens dont la profession (P106) est scientifique (Q901) , mais aussi ceux dont la profession est une sous-classe (P279) de scientifique.
Cela se formule comme cela :
?personne wdt:P106/wdt:P279* wd:Q901 .
L’étoile sert à indiquer qu’on veut prendre plusieurs niveaux de sous-classe s’il y en a.
La requête finale est donc :
PREFIX bd: <http://www.bigdata.com/rdf#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX wd: <http://www.wikidata.org/entity/> PREFIX wdt: <http://www.wikidata.org/prop/direct/> select distinct ?personne ?personneLabel where { ?personne wdt:P31 wd:Q5 . ?personne wdt:P21 wd:Q6581072 . ?personne wdt:P106/wdt:P279* wd:Q901 . SERVICE wikibase:label { bd:serviceParam wikibase:language "fr,en" . } } LIMIT 10
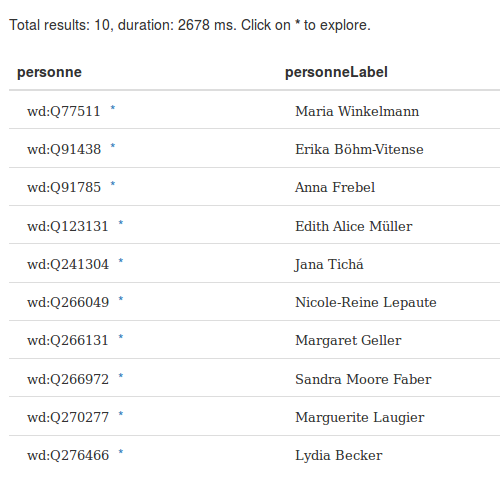
Résultat de la requête
Note : on peut abréger cette requête en remplaçant les trois lignes du WHERE par une seule :
?personne wdt:P31 wd:Q5 ; wdt:P21 wd:Q6581072 ; wdt:P106/wdt:P279* wd:Q901 .
C’est bien, mais ce qu’on voulait à la base, c’est le *nombre* de femmes scientifiques, pas dix d’entre elles au hasard. Il suffit de changer la ligne 5 de la façon suivante :
SELECT (COUNT(DISTINCT ?personne) AS ?nombre)
On demande donc à SPARQL de compter le nombre de résultats de notre requête et de le renvoyer en tant que nouvelle variable ?nombre, ce qui donne ce résultat https://w.wiki/4AHR
Au moment où j’écris ces lignes, il y a donc 16764 femmes scientifiques sur Wikidata. Et si on veut comparer aux hommes ? Il est possible de sortir le chiffre par genre en mettant cette valeur comme une variable et en l’utilisant pour grouper les résultats. Cela se fait de la façon suivante :
PREFIX bd: <http://www.bigdata.com/rdf#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX wd: <http://www.wikidata.org/entity/> PREFIX wdt: <http://www.wikidata.org/prop/direct/> PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> select ?genre (count(distinct ?personne) as ?nombre) where { ?personne wdt:P31 wd:Q5 ; wdt:P21 ?genre ; wdt:P106/wdt:P279* wd:Q901 . SERVICE wikibase:label { bd:serviceParam wikibase:language "fr,en" . } } GROUP BY ?genre LIMIT 10
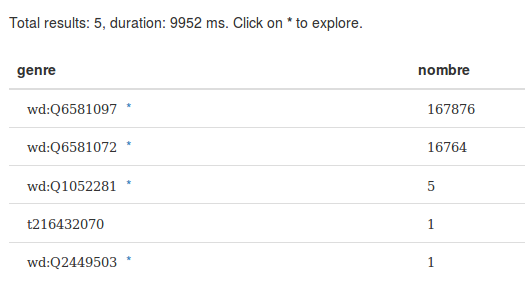
Résultat de la requête
Quelques remarques :
- j’ai dû renoncer à afficher les labels pour les genres, cela faisait partir la requête en timeout. Les valeurs sont les suivantes : masculin (Q6581097), féminin (Q6581072), femme transgenre (Q1052281), homme transgenre (Q2449503)
- Les personnes trans* sont généralement indiquées à la fois comme de sexe masculin et féminin (avec des dates de début ou de fin correspondant à la transition) et de genre femme (ou homme) transgenre. Comme il y a une seule propriété pour sexe et genre, elles apparaissent donc 3 fois dans ces statistiques.
- le t216432070 est en fait un blank node, c’est à dire un nœud vide. Il correspond à Āpastamba, un mathématicien indien du IV ou Ve siècle avant notre ère, qui a « valeur inconnue » pour la propriété sexe ou genre (ce qui me semble une erreur, quelques recherches sur Internet pointent toutes vers un homme.)
Par rapport à la question d’origine, il ne reste donc plus qu’à filtrer les résultats pour ne garder que les éléments qui ont un interwiki vers la Wikipédia en français. On cherche donc la propriété schema:about en filtrant sur les URL concernant fr.wikipedia.org :
PREFIX bd: <http://www.bigdata.com/rdf#> PREFIX wikibase: <http://wikiba.se/ontology#> PREFIX wd: <http://www.wikidata.org/entity/> PREFIX wdt: <http://www.wikidata.org/prop/direct/> PREFIX schema: <http://schema.org/> select ?genre (count(distinct ?personne) as ?nombre) where { ?personne wdt:P31 wd:Q5 ; wdt:P21 ?genre ; wdt:P106/wdt:P279* wd:Q901 . SERVICE wikibase:label { bd:serviceParam wikibase:language "fr,en" . } ?article schema:about ?personne . FILTER (SUBSTR(str(?article), 1, 25) = "https://fr.wikipedia.org/") . } GROUP BY ?genre LIMIT 10
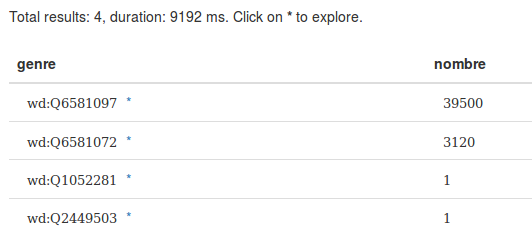
Résultat de la requête
Bilan : 7,6% de scientifiques sont des femmes sur la Wikipédia en français, contre 10% sur Wikidata. Cela a un peu progressé par rapport au précédent billet il y a sept mois.
PS : Merci à Karima Rafes pour sa présentation du langage SPARQL hier lors du SemanticCamp Paris #7.
Image d’en-tête:
Ada Lovelace par Margaret Carpenter (domaine public). L’editathon Femmes de sciences a lieu dans le cadre de l’Ada Week qui est nommée en son honneur.
{kind=link}
Jean-Fred 19 octobre 2015 02:22 ¶
Intéressant. Thanks for writing :)