Bon anniversaire, Wikidata !
Wikidata a quatre ans aujourd’hui, et il me semble que c’est le bon moment pour faire un petit retour sur mon expérience avec ce projet[1] .
Wikidata est un projet qui m’intéresse vivement depuis bien longtemps avant sa création effective. Si j’avais lu le nom ici et là sur le bistro de Wikipédia depuis que j’ai commencé à contribuer en 2005, la première fois qu’il a retenu mon attention, pour autant que je m’en souvienne, est cette discussion en novembre 2006[2] : un dépôt commun pour les données, fonctionnant de la même façon que Commons, c’était exactement ce qui manquait à Wikipédia !
Et je n’étais apparemment pas le seul à avoir cet avis : c’était à l’époque l’opinion générale sur le bistro. Un autre avantage qui y était mentionné à l’époque, c’était que cela pourrait remplacer avantageusement le système de catégories foireux de l’époque (enfin… l’actuel quoi.) Une fonctionnalité que je suis toujours impatient de voir arriver.
Avec le temps, je suis devenu de plus en plus impliqué dans la communauté, et pour finir j’ai sauté dans le wiki-train pour Gdańsk en 2010 pour participer à ma première Wikimania.
*Record scratch* Yup, that’s me. You’re probably wondering how I ended up in this situation. (Wiki-train Poznan dinner, Deryck Chan, CC-BY-SA 3.0)
{kind=link}

Là, l’une des présentations dont je me souviens le plus[3] était celle d’un système centralisé pour la gestion des liens interwiki. Cette présentation ne faisait à l’époque aucune mention d’autre (méta-)données que les interwikis et éventuellement des libellés lisibles dans plusieurs langues, et ne parlait pas du tout de Wikidata. Pourtant, ces deux choses sont ce qui est devenu la « phase l » du développement de Wikidata le 29 octobre 2012. Quand j’ai commencé à y contribuer, le 17 décembre de la même année, le projet était encore naissant et ne permettait toujours de faire que ces deux choses : gérer les interwikis de Wikipédia, et mettre des libellés. C’est donc ce que j’ai fait : J’ai créé un nouvel élément, lui ai donné une paire de libellés et ait déplacé les liens externes depuis Wikipédia.
Ta-da !
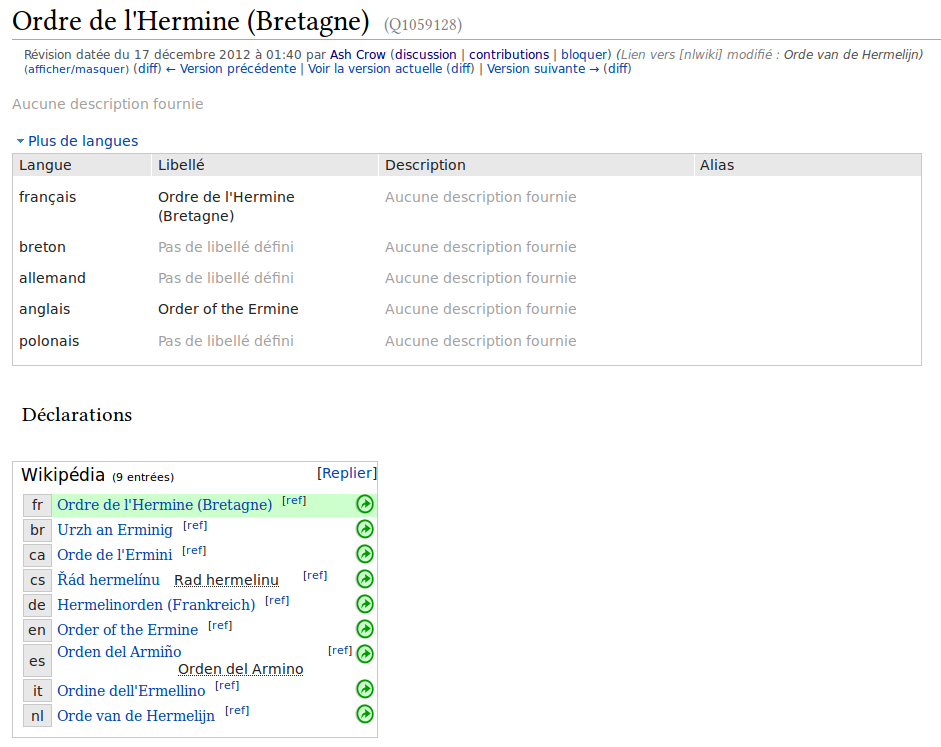
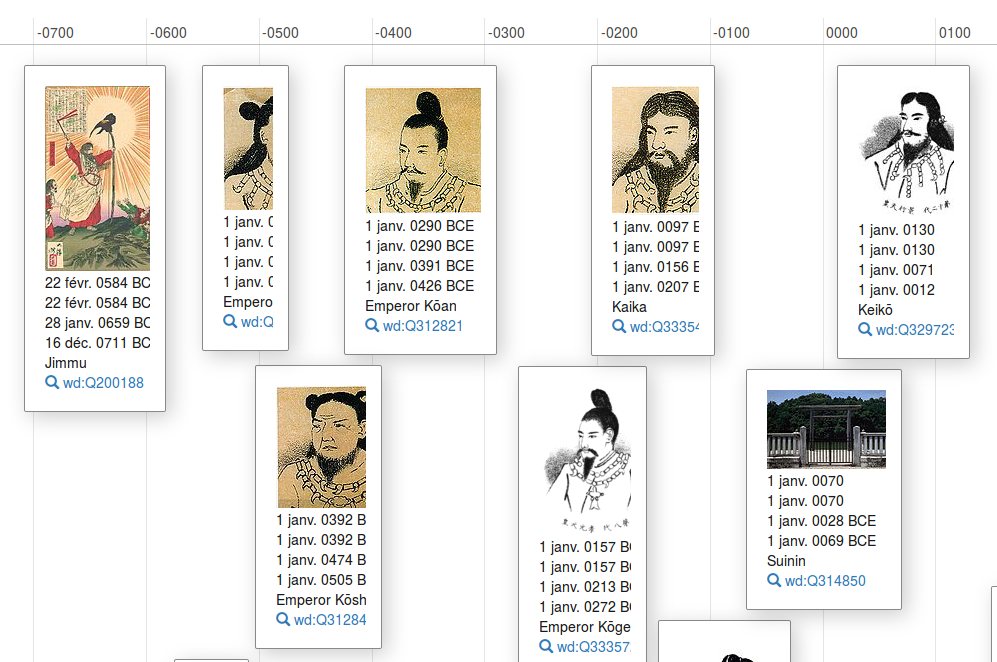
Je me suis arrêté là à l’époque. Il n’y avait alors aucun moyen d’ajouter des déclarations plus utiles, et n’ayant pas la passion de la gestion des interwikis, j’ai laissé cette tâche aux robots et à leurs dresseurs. Pendant longtemps après ça, j’ai simplement fait des modifications par-ci par-là, mais sans m’atteler à un gros projet. J’avais cependant envie de passer au cran supérieur, et je me suis donc demandé à quoi m’atteler… En 2006 ou 2007, j’avais refait entièrement la liste des empereurs du Japon sur Wikipédia, et je me suis dit que ça pourrait être une bonne idée d’avoir les mêmes données de base (c’est-à-dire noms, dates de naissance/règne/mort, lieux de naissance et de mort, etc.) sur Wikidata également.
À l’époque, j’utilisais très peu d’outils ou de gadgets, et ça a donc été assez long et fastidieux (et sans l’outil missingprops.js de Magnus[4] , ça l’aurait été encore plus), mais j’ai fini par en voir le bout.
Les empereurs légendaires (voir la frise complète)
Mon pic d’activité suivant a eu lieu quelques temps plus tard, quand j’ai décidé de créer chaque corps céleste de l’univers de Serenity/Firefly[5] . Le faire uniquement avec l’interface de Wikidata aurait relevé de la folie pure, et j’ai donc utilisé un autre outil de Magnus : QuickStatements. Si vous vous en êtes déjà servi, vous savez qu’une simple textarea où coller un blob de tab separated values n’est pas l’interface la plus pratique du monde… Du coup, j’ai décidé à l’époque de créer un outil moi-même pour résoudre le problème : un convertisseur CSV vers QuickStatements qui permet de travailler avec un tableur organisé de façon plus traditionnelle.
Après ça, parmi d’autres choses, j’ai décidé d’importer tous les épisodes d’xkcd, et également aidé Harmonia Amanda dans son travail avec les courses de chiens de traîneaux puis les écoles d’art dramatique. Cela m’a incité à me plonger plus avant dans Python et écrire des scripts pour récupérer et traiter les données.

Je sais que vous êtes tous fans d’xkcd. (xkcd 285, Randall Munroe, CC-BY-SA 2.5)
{kind=link}
Dans l’intervalle, j’ai également suivi la première édition du MOOC d’Inria sur le web sémantique, durant lequel j’ai appris plein de choses, et en particulier le langage SPARQL. Et là, c’est vraiment parti en roue libre : quand le point d’accès SPARQL pour Wikidata a été mis à disposition, j’ai écrit un billet ici à ce sujet. Des gens ont commencé à me poser des questions dessus, ou à me demander d’écrire des requêtes pour eux, et cet article est devenu le premier d’une longue série qui continue encore avec les #SundayQuery.
En résumé, en quatre ans :
- J’ai commencé à coder des outils et les mettre à disposition de la communauté
- J’ai écrit des scripts d’extraction et conversion de données en Python
- J’ai beaucoup appris sur le web sémantique
- Je suis devenu un ninja du SPARQL.
Et tout ça à cause de Wikidata. Et j’espère bien que ça va continuer sur cette lancée !
Image d’en-tête:
Wikidata Birthday Cake par Jason Krüger (CC-BY-SA 4.0)
{kind=link}