Ajout de la galerie d'images et récupération d'anciens contenus
Depuis quelques mois, je consacre une partie de mon temps libre à l'intégration sur ce site de contenus que j'ai publiés ailleurs au cours de mes... un peu plus de vingt ans de présence sur Internet maintenant... Ça nous rajeunit pas ^^'
Tout d'abord, la récupération d'une partie de mon ancien blog de dessin. Ensuite, les dessins publiés sur DeviantArt, et les photos publiées sur Flickr et Instagram (j'ai aussi regardé du côté de Facebook mais il n'y a a priori pas grand chose à récupérer)
Récupération du blog
Capture d'écran de la catégorie "Vie du site" sur Tenshisama, via archive.net. Il manque une partie de la mise en page.
Entre 2005 et 2008, j'ai tenu, à quatre mains avec Lowenael, un blog Dotclear nommé Tenshisama (ou Tenshi-Sama), essentiellement centré sur le dessin, mais où on parlait plus largement d'un peu tout : c'était à la grande époque des blogs, avant que les réseaux sociaux changent fondamentalement la façon de raconter sa vie sur les Internets[1] .
Ce n'était pas mon premier blog, j'en avais eu un avant fait complètement à la main (y compris les pages html), mais à ma connaissance celui-ci est entièrement perdu[2] .
Il y a quelques mois, je suis tombé en parcourant un vieux disque dur de 2012 sur des sauvegardes a priori complètes de Tenshisama, sous la forme d'un dossier comportant toute l'arborescence des fichiers ainsi qu'un fichier "blog-backup.txt" qui était en fait un export de la base de données sous forme d'une série de CSV (un pour chaque table) collés les uns à la suite des autres.
Impossible d'importer ça dans une version moderne de Dotclear, mais j'ai pu écrire un script pour importer ça dans ce blog Wagtail, relativement facilement, même si ça m'a pris pas mal de temps pour comprendre la structure de l'un et de l'autre. J'ai pu récupérer tout ce qui m'intéressait (mes propres billets, ainsi que leurs images, catégories, tags, commentaires…) et je me suis même amusé avec un générateur d'images procédurales pour générer des images d'en-tête, puisque j'en ai besoin ici.
Un billet importé du vieux blog dans l'actuel
Le résultat est visible dans la catégorie Tenshisama du blog :)
Création de la galerie
J'avais depuis longtemps envie de créer une galerie d'images pour ce site. Le passage à Wagtail est très pratique pour ça : le fait qu'il gère par défaut une installation « multi-sites » permet de mettre ça sur un sous-domaine dédié très facilement, et la structure de la galerie allait être relativement proche de celle du blog, ce qui me permet de reprendre en partie les modèles déjà présents, et de partager certaines fonctions utilitaires entre les deux. Comme c'est du Django, il est également très facile de faire évoluer les modèles de page au fur et à mesure que j'ai besoin de nouvelles fonctionnalités.
Bulma m'a aussi pas mal facilité la vie en ayant déjà des composants pour quasiment tout ce que je veux faire niveau style.
Je savais déjà que j'allais reprendre les galeries du blog, ainsi que les images publiées sur DeviantArt, Flickr et Instagram, et j'avais donc besoin de certaines fonctionnalités :
- gérer plusieurs galeries (en l'occurrence, après quelques hésitations, j'ai choisi d'en faire seulement deux, une le dessin, une pour la photo) ;
- mettre les images dans des albums, c'est-à-dire des collections non-exclusives d'images qui peuvent avoir une description et une image d'en-tête ;
- ajouter des tags aux images ;
- importer les commentaires (en tout cas ceux pertinents) et le nombre de likes.
J'ai pu faire une première base assez rapidement, en reprenant largement ce que j'avais déjà fait pour le blog et pour le site pro.
J'ai ensuite procédé par étapes au fur et à mesure des imports d'image depuis les différentes archives.
Récupération de la galerie d'images de Tenshisama
Capture d'écran d'une image dans la galerie de Tenshisama via archive.org (l'accueil de la galerie n'a pas été archivé)
La première étape a été la récupération de ma galerie de dessins hébergée sur Tenshisama. Ici, pas de grandes difficultés : la structure était la même que celle du blog lui-même (juste un autre type de page) et j'ai donc pu largement réutiliser le script d'import de ce dernier.
Par contre, ça a été une vraie plongée en apnée dans les souvenirs de l'époque, et je me suis un peu demandé comment organiser les contenus. J'ai fini par scinder en quatre albums :
- Dessins colorisés : mes dessins complets avec encrage et colorisation ;
- Croquis : les simples croquis au crayon ou au bic ;
- Linearts : les linearts, c'est-à-dire les dessins encrés prêts à coloriser[3] ;
- Colorisations : mes colorisations sur des linearts d'autres personnes.
En fouillant dans les dossiers, j'ai également retrouvés des dessins et photos qui n'apparaissaient pas dans les galeries elles-mêmes mais dans des mini-galeries présentes dans les billets du blog. J'ai fait un script pour importer une partie de ces images (en excluant celles trop perso, par exemple les sorties entre allfanartistes.)
L'essentiel de ces contenus viennent de choses que j'ai publiées à l'époque sur Allfanarts, donc une partie des dessins sont en fait plus vieux que les dates de publications sur le blog.
Notamment, j'ai récupéré les images de Cross Destinies: Abred, un projet perso de jeu vidéo avec RPG Maker 2003 que j'avais dû commencer quand j'étais à l'IUT[4]

Pochette de Cross Destinies: Abred
Les fichiers récupérés sont visibles sous le tag "Tenshisama".
Récupération des images sur DeviantArt
Capture d'écran de mon profil DeviantArt
DeviantArt est une des raisons principales pour laquelle je voulais récupérer mes images à un endroit sous mon contrôle. En effet, il y a eu en 2021-2022 une grosse vague d'arnaqueurs qui aspiraient des collections entières d'images depuis DeviantArt pour en faire des NFT et les vendre sur OpenSea. La réponse de DeviantArt a été à la fois très lente et plutôt molle : au bout de plusieurs mois, ils ont sorti un outil qui vérifie et prévient si un de nos dessins a été transformé en NFT... mais uniquement si on paie.
Ils ont ensuite enchaîné sur une autre connerie : la création d'un générateur d'images IA qui se base sur les images qu'ils hébergent, et qui a au début été basé sur un système en opt-out : nos créations étaient pompées par défaut sauf à dire explicitement qu'on ne voulaient pas. Devant la colère de la communauté, ils ont fini par passer en opt-in.
J'ai donc, plein d'espoir, utilisé l'outil fourni pour l'export des données dans le cadre du RGPD… mais il ne contient que des données comme mes paramètres ou la liste des IPs que j'ai utilisées[5] . J'ai envisagé de passer par l'API mais entre les « déviations » (dessins et photos finis) et les « scraps » (croquis), il y n'y avait qu'une dizaine d'images et j'ai fini par simplement les importer à la main avec le tag qui va bien.
Récupération de la galerie Flickr
Capture d'écran de mon profil Flickr
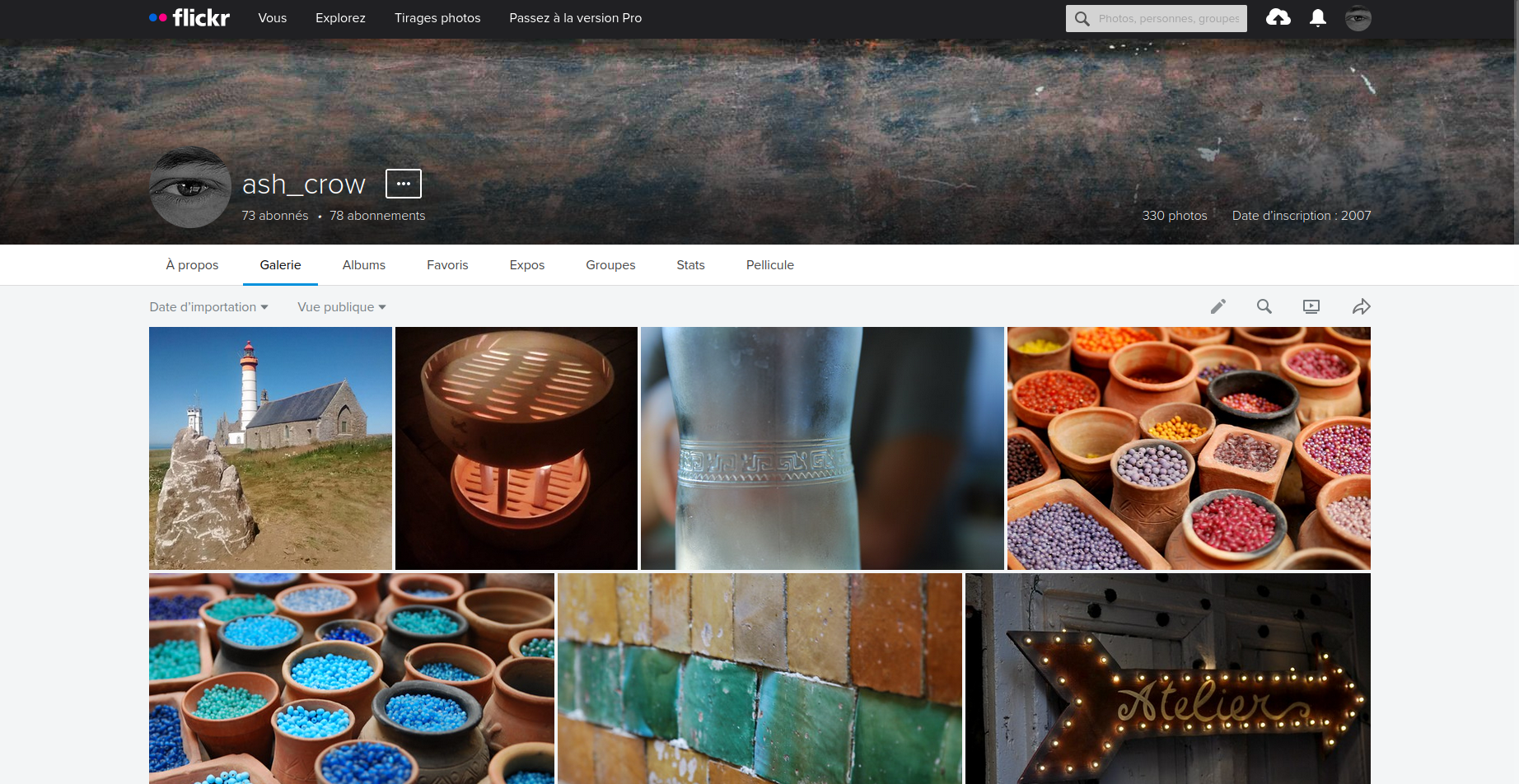
L'étape suivante était ma galerie Flickr, de loin la plus importante en terme de nombre d'images à récupérer (plus de 300), mais un peu abandonnée depuis quelques années.
Heureusement, vu la quantité, l'export fourni via un bouton très visible directement sur la page des paramètres est à la fois très complet et très pratique, avec un fichier JSON par image contenant absolument toutes les informations dont j'avais besoin :
- identifiant
- titre
- description
- date de prise de vue et date de publication
- nombre de favoris
- lien vers la page
- licence
- coordonnées géographiques si elles ont été renseignées
- albums et tags
- commentaires
(cf. exemple ci-dessous)
{ "id": "387868039", "name": "Broons - Colonne du Guesclin", "description": "en:A column in memory of Bertrand du Guesclin in Broons, France.\n\nfr:Une colonne \u00e9rig\u00e9e en m\u00e9moire de Bertrand du Guesclin \u00e0 Broons, en France.", "count_views": "432", "count_faves": "0", "count_comments": "1", "date_taken": "2005-09-06 17:35:47", "count_tags": "2", "count_notes": "0", "rotation": 0, "date_imported": "2007-02-12 03:52:39", "photopage": "https://www.flickr.com/photos/ash_crow/387868039/", "original": "https://live.staticflickr.com/150/387868039_c44db74339_o.jpg", "license": "Attribution-ShareAlike License", "geo": [ { "latitude": "48333658", "longitude": "-2265243", "accuracy": "13" } ], "groups": [ ], "albums": [ { "id": "72157662355776533", "title": "Bretagne(s)", "url": "https://www.flickr.com/photos/ash_crow/sets/72157662355776533/" } ], "tags": [ { "tag": "Broons", "user": "https://www.flickr.com/photos/ash_crow/", "date_create": "2007-02-12 03:52:39" }, { "tag": "Guesclin", "user": "https://www.flickr.com/photos/ash_crow/", "date_create": "2007-02-12 03:52:39" } ], "people": [ ], "notes": [ ], "privacy": "public", "comment_permissions": "any flickr member", "tagging_permissions": "people you follow", "safety": "safe", "comments": [ { "id": "72157628016703243", "date": "2011-11-16 08:22:50", "user": "54664961@N08", "comment": "Conn\u00e9table de France, n\u00e9 \u00e0 200 m\u00e8tres du monument!", "url": "https://www.flickr.com/photos/ash_crow/387868039//#comment72157628016703243" } ] }
Honnêtement, c'est l'étalon à partir duquel je vais juger les exports des autres sites. Avec tout ça, il m'a été relativement simple de faire un script pour récupérer tout ça et importer les données.
Cerise sur le gâteau, les métadonnées EXIF des photos sont également présentes, et j'ai donc pu ajouter une fonction pour afficher les informations relatives à l'appareil sur la page de description des images.
Capture d'écran d'une photo dans la galerie, avec les informations sur l'appareil photo
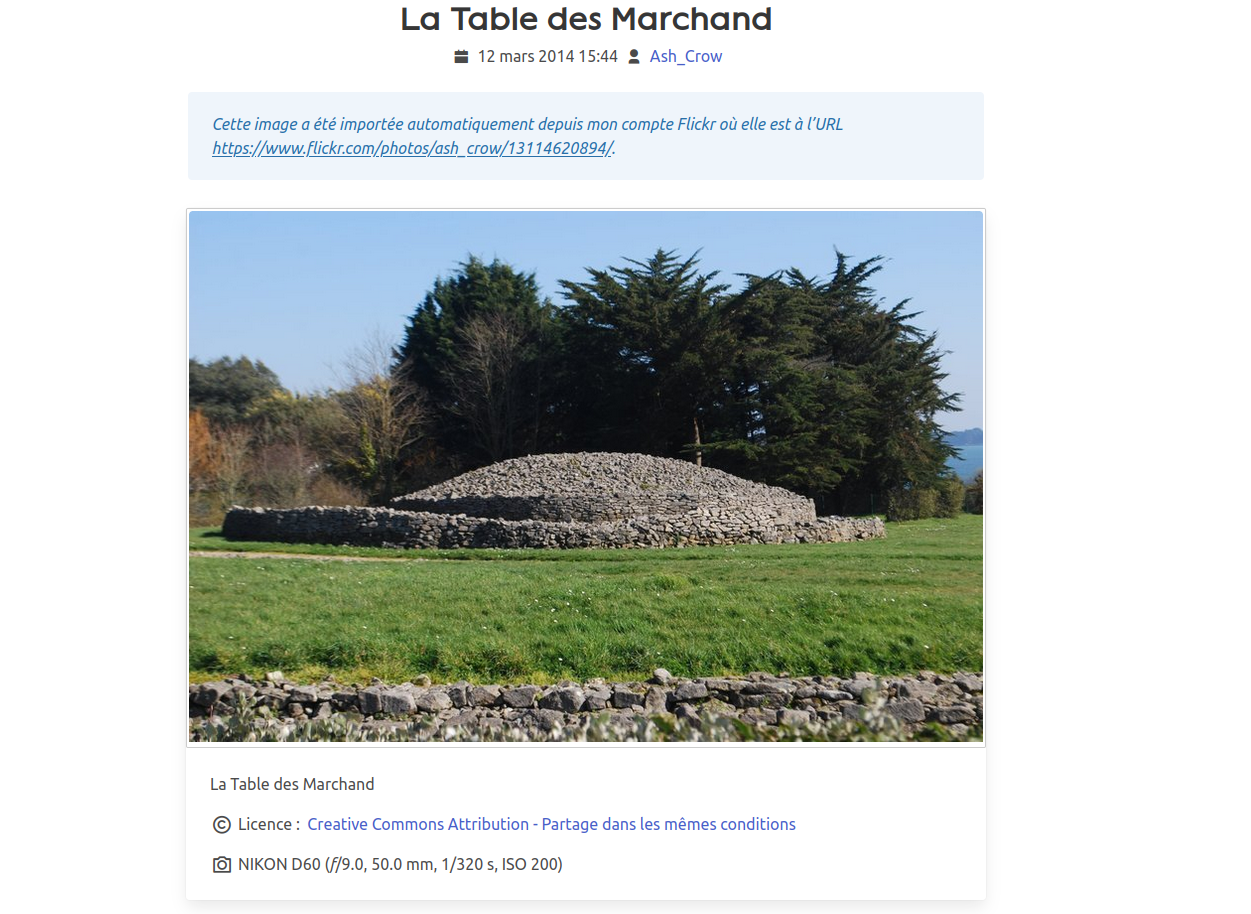
Tout ça est visible sous le tag "Flickr".
Récupération de la galerie Instagram
Capture d'écran de mon profil Instagram
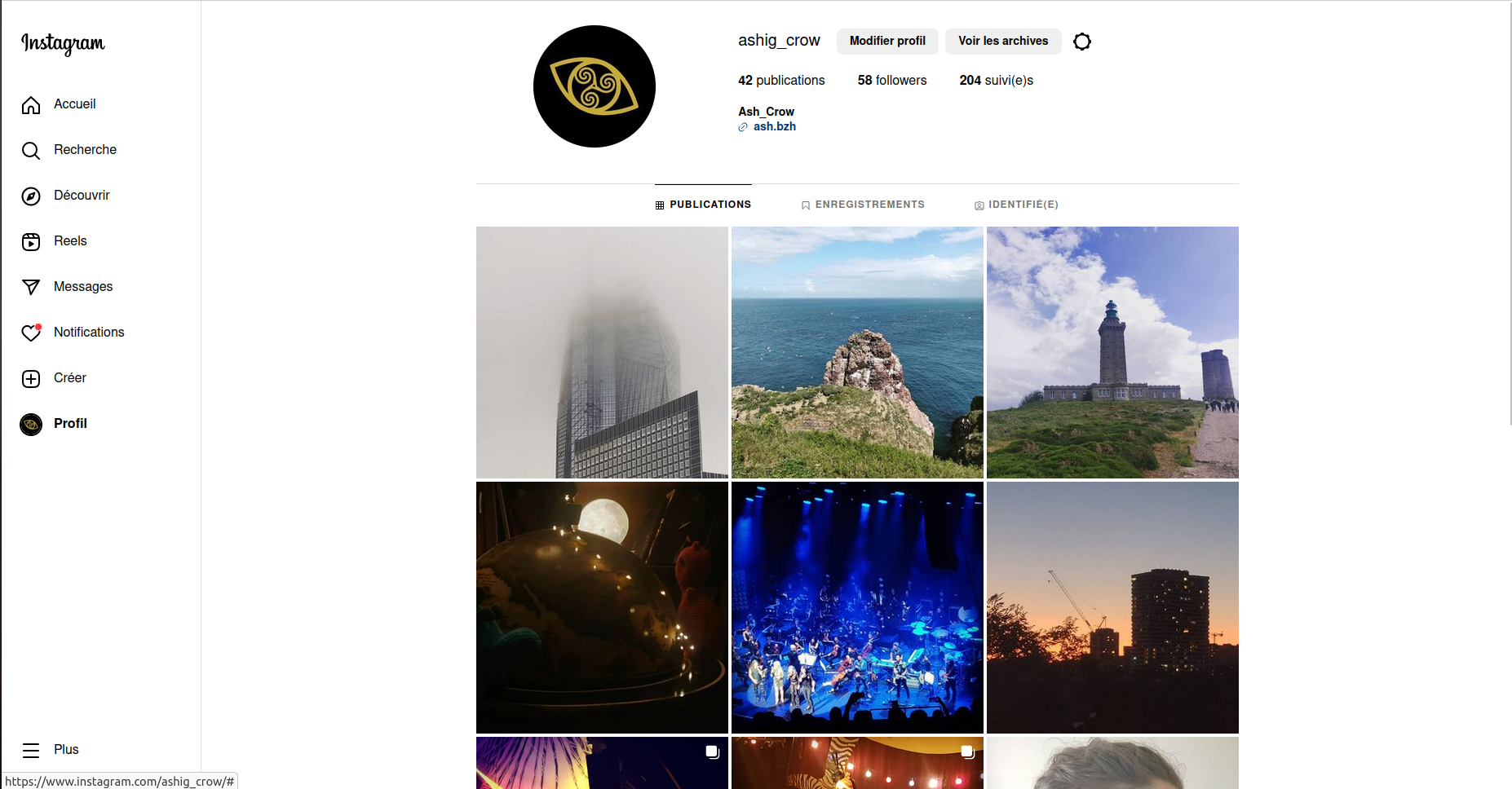
Dernière étape, l'importation de la galerie Instagram. Là encore, j'ai fait l'export des données via les outils fournis pour le respect du RGPD[6]
. Là aussi, l'export fourni est assez extensif mais il n'y a qu'un fichier réellement intéressant, celui nommé posts_1.json. Le problème, c'est qu'il est très loin d'être complet. D'une part, Instagram est plus basique que Flickr et ne contient qu'un champ combinant titre, description et hashtags ; et d'autre part il manque certaines informations clefs dans l'export à commencer par le lien vers la publication sur Instagram lui-même (!), mais aussi les commentaires ou le nombre de likes. Il est également possible de poster des images sans titre du tout, ce qui ne me va pas non plus.
De plus, Instagram a rendu très difficile l'utilisation d'outils d'exports tiers dans une tentative pour lutter contre le scrapping, et a déjà bloqué les comptes de personnes tentant d'en utiliser.
Dans la mesure où il n'y a qu'une cinquantaine d'images en tout, j'ai donc pris le parti de compléter le fichier à la main, en ajoutant des champs "post_url", "likes", "description" et "hashtags" et en modifiant les titres là où c'était nécessaire, et une nouvelle fois écrit un script d'import pour exploiter le résultat, disponible sous le tag "Instagram".
{ "post_url": "https://www.instagram.com/p/BEGHrxByW18/", "likes": 3, "media": [ { "uri": "media/posts/201604/12328046_1702676563354905_869520216_n_17846576008108481.jpg", "creation_timestamp": 1460454264, "title": "Jusqu'au bout du bout du monde....", "description": "La Pointe du Raz" } ], "hashtags": [ "Bretagne" ] },
La suite
Côté contenus, il me reste encore des trucs à récupérer par-ci par-là : il faudrait notamment que je me plonge dans mes publications sur Twitter pour identifier les photos et dessins qui valent le coup d'être republiés... Mais honnêtement flemme un peu (mise à jour 30/07 : C'est finalement fait, ainsi que Reddit. Je me suis dit que je n’allais pas attendre que les proprios des sites finissent de casser leurs jouets pour m’y pencher.)
Il faudrait aussi que je regarde du côté de mes imports sur Wikimedia Commons, où j'ai publié pas mal d'images qui doivent valoir le coup d'être gardées.
À ce niveau, ce n'est plus une priorité et c'est probablement quelque chose que je ferai petit à petit. Pour le moment, je suis plutôt content d'avoir reconstitué et centralisé à un endroit qui m'appartient une bonne part de ma présence sur Internet ces deux dernières décennies.
N'hésitez pas à aller voir les archives du blog et la galerie.
Accueil de la galerie
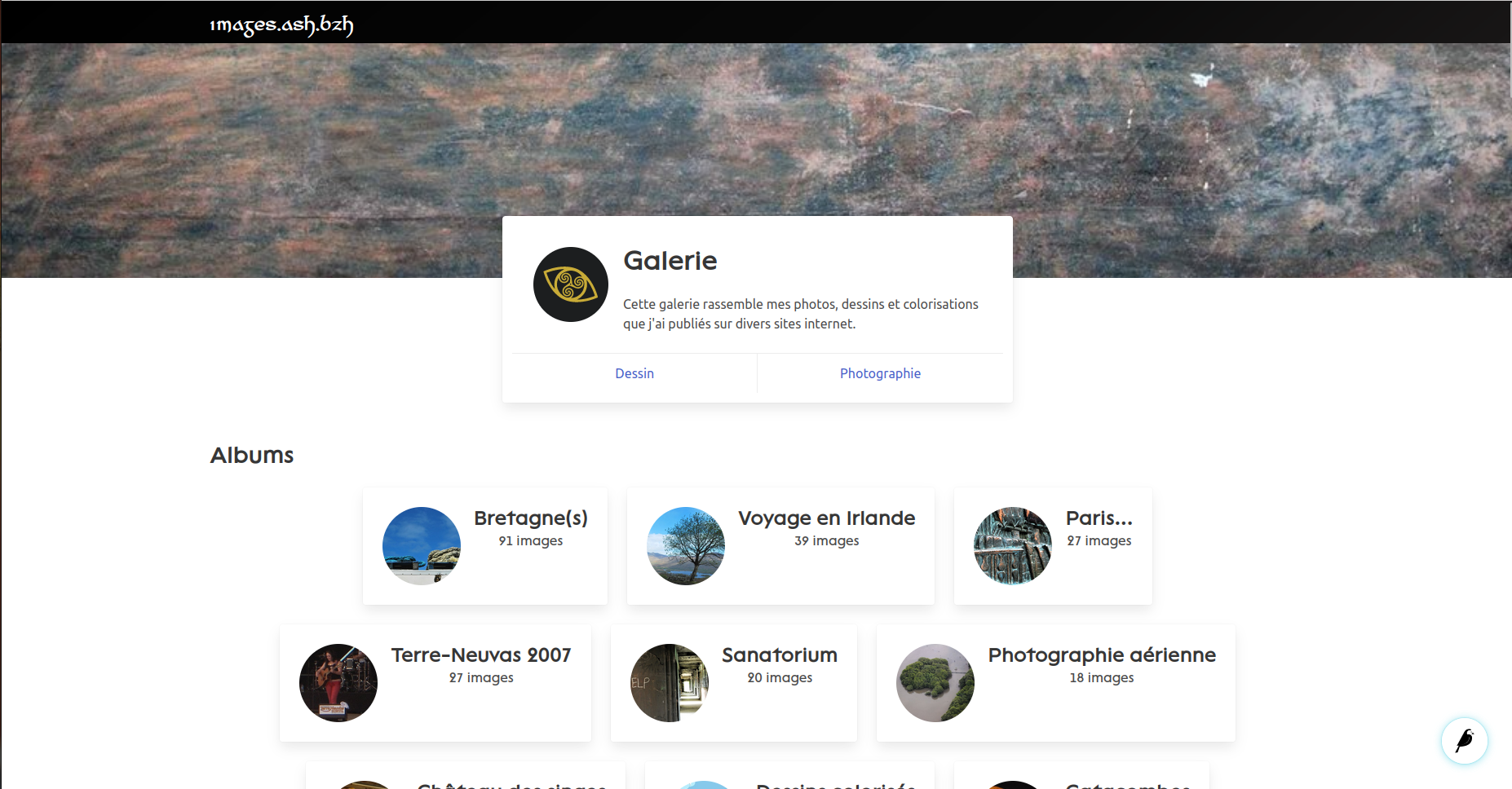
Conclusion
Faire cet import m'a permis de comparer la façon dont diverses plateformes abordent la question des exports pour application du droit à l’interopérabilité garanti par le RGPD, allant du néant complet (DeviantArt) à un export entièrement auto-suffisant (Flickr), en passant par des intermédiaires qui répondent probablement aux exigences légales, mais nécessitant du bricolage manuel.
Il serait vraiment utile d'avoir un standard commun pour l'export de ce genre de contenu, par exemple basé sur la norme ActivityPub du W3C (utilisée par les applications du Fediverse comme Mastodon) : en espérant que cette standardisation vienne dans les années à venir (cela nécessitera sans doute une nouvelle mouture du RGPD pour l'imposer aux géants du web cela dit.)
Image d’en-tête:
Rosace de la cathédrale de Saint-Malo (travail personnel, CC-BY-SA)