Croiser des données avec OpenRefine
On vient de me poser une question intéressante sur Twitter :
Question pour les experts Wikidata qui causent SPARQL : vous pourriez m'aider à faire une requête du genre « villes des États-Unis entre 100 000 et 600 000 habitants situées dans un comté ayant majoritairement voté pour Clinton en 2016 » ?
— Guillaume Paumier (@gpaumier) July 19, 2020
Le problème ici est que les données électorales détaillées ne sont pas sur Wikidata (et à mon avis n’y ont pas leur place, elles seraient mieux sur Commons sous forme de données tabulaires).
En revanche, il est possible d’extraire via une requête SPARQL la liste des villes des États-Unis entre 100 000 et 600 000 habitants, puis de la croiser par le biais d’OpenRefine avec un tableau des résultats des élections.
Données électorales
La première étape est de chercher un fichier open data contenant les données de l’élection présidentielle américaine de 2016 par comté, idéalement sous la forme d’un CSV à télécharger. Ça tombe bien, il y en a un sur OpenDataSoft.
Plus qu’à l’importer dans OpenRefine. Si vous ne connaissez pas, c’est un outil d’alignement et de croisement de données, qui se définit lui-même comme un « Excel sous stéroïdes ». Il était développé à la base par Google pour Freebase, mais il a depuis été libéré et le développeur principal actuel est un contributeur à Wikidata. Il y a de bons tutoriels pour l’utiliser pour récupérer des données de Wikidata ou y importer de nouvelles données après alignement avec les données existantes, mais on ne va ici faire ni l’un ni l’autre.
Dans OpenRefine, il faut faire CreateProject → from this computer et choisir le CSV téléchargé, puis cliquer sur Next.
Capture d’écran d’OpenRefine
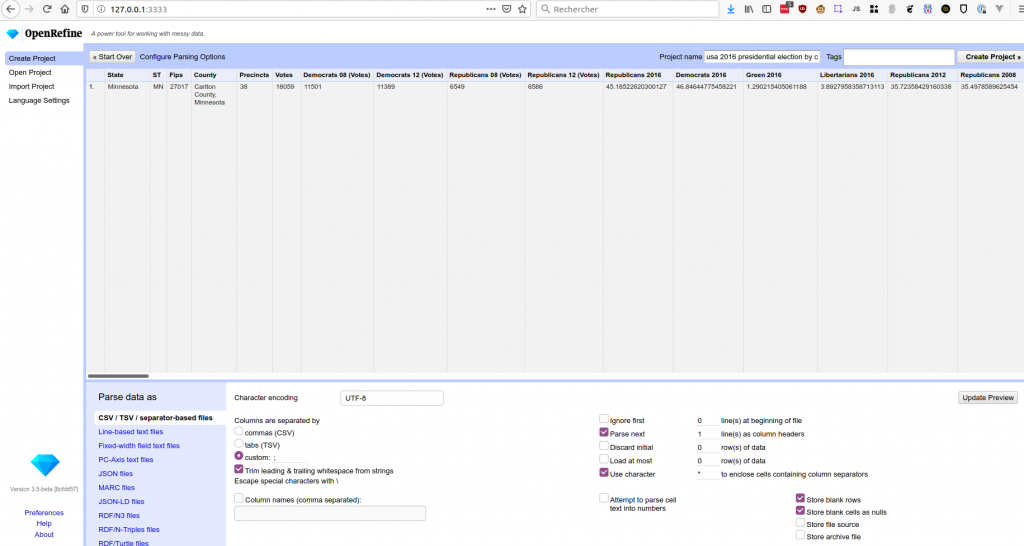
La prévisualisation semble correcte, et le nom du projet proposé (celui du fichier) également : je clique donc sur Create project.
Les informations qui vont être importantes pour la suite sont : le nom du projet, le nom de la colonne servant à aligner les données (la colonne « County », qui est du format « <County>, <State> ») et celui de la ou des colonnes avec les données à récupérer (ici, uniquement la colonne « Democrats 2016 ») Le jeu de données est déjà bon pour ce que je veux en faire, je n’ai pas de manipulations supplémentaires à faire.
Liste des villes
La seconde étape est d’extraire la liste des villes correspondant à la demande. Je ne vais pas détailler la requête, mais en regardant quelques entrées de villes US sur Wikidata, je vois qu’elles ont pour nature « city aux États-Unis » (Q1093829), qu’elles ont des chiffres de population pour 2010, le comté entré comme « localisation administrative » (je vais quand même vérifier qu’il a s’agit bien d’un comté américain et pas directement de l’état ou d’un autre type de division administrative. Apparemment tous ont pour nature « comté de <tel état> », qui sont eux-mêmes des sous-classes de « comté des États-Unis »)
Je vais aussi avoir besoin de l’état et, tant qu’à faire, je récupère aussi les coordonnées. Voici donc la requête :
#Cities of the United States between 100,000 and 600,000 inhabitants with the counties and states they are located in SELECT DISTINCT ?city ?cityLabel ?county ?countyLabel ?state ?stateLabel ?pop ?coord WHERE { ?city wdt:P31 wd:Q1093829; wdt:P1082 ?pop. FILTER((?pop >= 100000 ) && (?pop <= 600000 )) ?city wdt:P131 ?county. ?county (wdt:P31/wdt:P279) wd:Q47168; wdt:P131 ?state. ?state wdt:P31 wd:Q35657. ?city wdt:P625 ?coord. SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } } ORDER BY (?stateLabel) (?countyLabel) (?cityLabel)
La requête renvoie 247 résultats alors qu’il y a 213 villes correspondant à la requête, parce que certaines villes s’étalent sur plusieurs comtés et qu’il y a parfois plusieurs chiffres de population ou plusieurs coordonnées géographiques entrés sur certains éléments de ville.
Je télécharge donc le résultat de la requête en CSV, que je vais également importer dans un projet OpenRefine que je nomme « US Cities between 100000 and 600000 hab. that voted democrat in the 2016 Presidential election » ce qui est… long.
Aligner les données
L’idée est d’enrichir ce nouveau projet avec les informations électorales de celui créé plus haut. On va donc créer une nouvelle colonne contenant le nom des comtés sous le même format « <County>, <State> »
Pour cela, je commence par dupliquer la colonne StateLabel en cliquant sur la flèche à côté du nom de la colonne, puis Edit column → Add column based on this column. Je nomme la nouvelle colonne « county state » et je vérifie que l’expression est simplement « value » (ce qui va donc juste copier la valeur actuelle)
Sur la nouvelle colonne county state, je fais Edit column → Join columns avec les paramètres suivants :
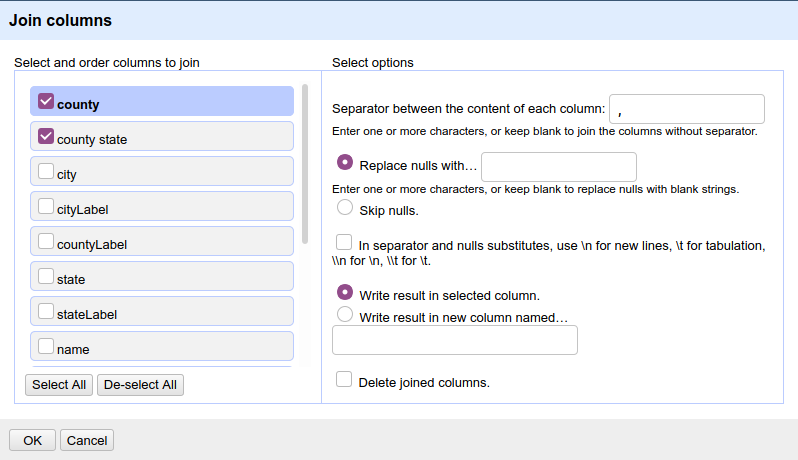
Capture d’écran d’OpenRefine
Attention, il y a une espace après la virgule dans le champ Separator. Une fois cela fait, on peut enfin aligner avec l’autre projet et récupérer les résultats des démocrates en 2016. Là encore, on crée une nouvelle colonne « Democrats 2016 » basée sur la colonne « county state », avec l’expression suivante :
toNumber(cell.cross("usa 2016 presidential election by county csv", "County").cells['Democrats 2016'].value[0])
Pour détailler : cell.cross("usa 2016 presidential election by county csv", "County") indique le nom du projet avec lequel on aligne et celui de la colonne pivot dans ce projet, cells['Democrats 2016'].value[0] récupère la valeur de la colonne Democrats 2016 et enfin la fonction toNumber(...) transforme cette valeur en nombre (sinon c’est une chaîne de caractères)
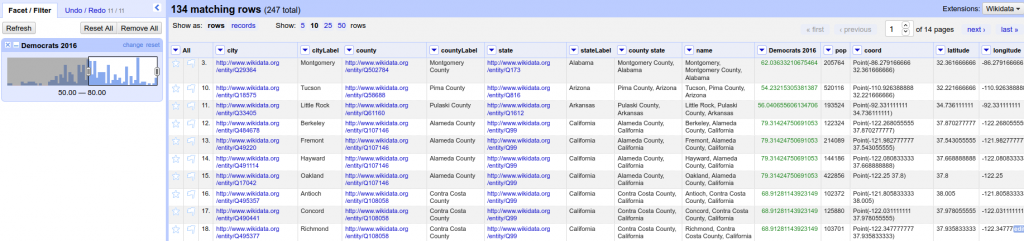
On peut maintenant filtrer les villes où les démocrates étaient majoritaires en 2016 ! Dans OpenRefine, cela se fait avec une facette. Sur la colonne Democrats 2016, Facet → Numeric Facet fait apparaître une glissière très pratique. Il suffit de déplacer la borne de gauche sur 50 et voilà, on a le résultat qu’on cherchait au début.
Capture d‘écran d’OpenRefine
Affichage dans uMap
On pourrait directement exporter ce résultat en CSV mais je veux l’afficher dans uMap, il reste donc quelques manips à faire pour correspondre au format attendu :
- Renommer (ou dupliquer) la colonne cityLabel en name
- Scinder la longitude et la latitude dans deux colonnes séparées et nommées comme ça. Il faut pour cela créer deux colonnes à partir de la colonne coord.
Pour la colonne longitude, l’expression (en jython) est :
import re match = re.match(r'Point(([0-9,-.]+) ', value) return match.group(1)
Et pour la colonne latitude :
import re match = re.match(r'Point([0-9-.]+ ([0-9-.]+))', value) return match.group(1)
On peut donc ensuite exporter le projet en CSV (Export → Comma separated values) puis l’importer dans une nouvelle carte sur uMap, et voici le résultat :
Capture d’écran d’uMap
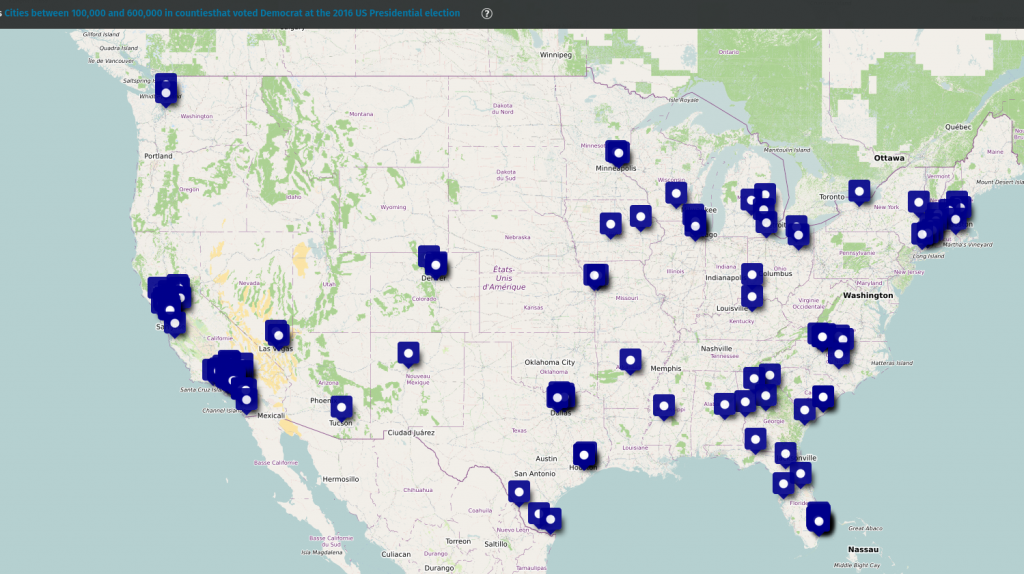
Image d’en-tête:
I´m ready for Hillary par Rafael Robles, CC-BY 2.0
.jpg){kind=link}
