Happy Birthday, Wikidata!
Wikidata turns four today, and I thought it would be a good time to make a little return on my experience with the project.[1]
Wikidata is a project I was enthusiastic for a long time before it went live. I’ve read the name here and there on the « bistro » (village pump) of the French Wikipedia since I started editing Wikipedia in 2005 but the first time it got my attention, IIRC was that discussion in November of 2006.[2] A common repository for data functionning the same way as Commons seemed to me the biggest thing missing to Wikipedia! Another useful thing that was discussed at that time was that it could entirely replace the flawed category system Wikipedia used at the time (oh wait… still uses.) That functionality is one I’m still impatient to see happening.
Time passed and I became more involved in the community, to the point I jumped on the Wikitrain to Gdańsk in 2010 to attend my first Wikimania.
*Record scratch* Yup, that’s me. You’re probably wondering how I ended up in this situation. (Wiki-train Poznan dinner, Deryck Chan, CC-BY-SA 3.0)
{kind=link}

There, one of the talks I remember the most[3] was about a centralized system for sitelinks. That talk made no mention of storing other data than sitelinks and maybe some system to have readable labels in different languages, but that two things became the « Phase I » of Wikidata developpement, and if I check back in my edit log, when I made my first edit was on the 17th of December, 2012, Wikidata was a 7 weeks old baby project that only managed these two things: Wikipedia’s sitelinks and labels. So that’s what I did: I created a new entry, gave it a couple of labels and moved the sitelinks here from Wikipedia.
Ta-da !
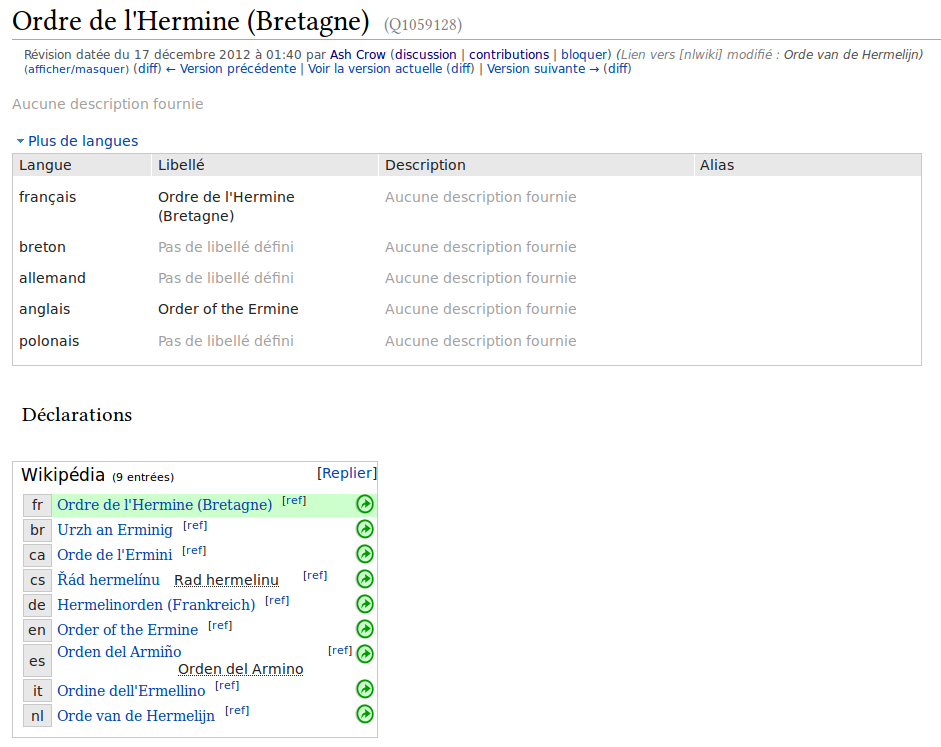
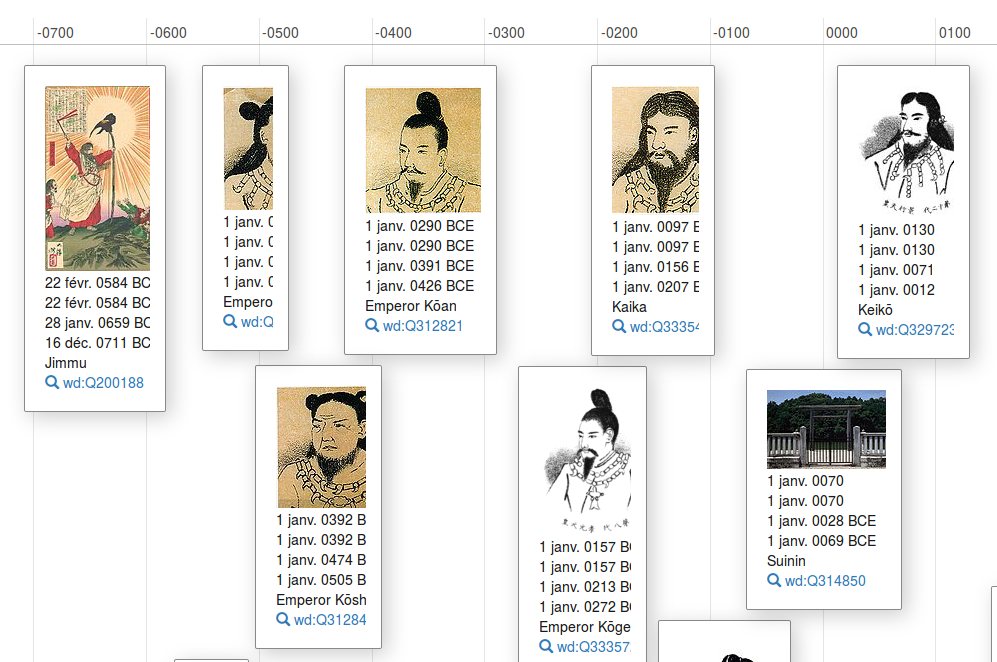
And that’s about it at this time. As there was no possibility to add more useful statements at that point, I left the mass import of sitelinks to bots and their masters. After that, and for a long time, I made few edits here and there, but no big projects. At some point, I wanted to do more and asked myself what to do… Back in 2006 or 2007, I remade the list of Emperors of Japan on the French Wikipedia, so I thought it would be a good idea to have the basic data about them on Wikidata as well (names, dates of birth/reign/death, places of birth/dates, etc.)
I used very few tools at that time, so it was long and tedious (and if it wasn’t for Magnus’ missing props.js and wikidata useful.js[4] , it would have been a lot harder.), but I managed to see the end of it.
The legendary emperors of Japan (see the full timeline)
My next burst of activity was sometime later, when I decided to create every single celestial body from the Serenity/Firefly universe. Doing it with Wikidata’s interface only would have been pure madness, so I decided to use another of Magnus’s tools; QuickStatements. If you’ve ever used it, you know that a textarea where to paste a blob of tab separated values isn’t the most practical interface ever, so that time I decided to create a tool of my own: a CSV to QuickStatements convertor that permits to use a more familiar interface.
After that, among other things, I decided to import all xkcd episodes, and also helped Harmonia Amanda with her work on sled dog races and drama schools. This required me to dig further into Python and write scrapers and data processing scripts.

I know you all are xkcd fans. (xkcd 285, Randall Munroe, CC-BY-SA 2.5)
{kind=link}
In the meantime, I also passed the Semantic Web Mooc from Inria, in which I learnt a lot about a lot of things, and in particular, SPARQL. And that’s when the things went crazy. When the SPARQL endpoint for Wikidata became live, I wrote an article here about SPARQL. People started to ask me questions about it, or to write queries for them, so that article became the first of a series which continues to these days with the #SundayQuery.
If I sum up, in these four years:
- I started to write my own tools and offer them to the community
- I created scrapers and converters in Python
- I learnt a lot about semantic web
- I became a SPARQL ninja.
All that because of Wikidata. And I hope this project will continue to make me do that type of crazy things.
Now, if you’ll excuse me, I think there is some birthday cake waiting for me.
Header image:
Wikidata Birthday Cake by Jason Krüger (CC-BY-SA 4.0)
{kind=link}