Ton prénom sur Wikidata
Parmi les milliers de trucs qu’il y a à faire sur Wikidata, un gros chantier est celui des prénoms. Cela dit, il y a un moyen simple de se partager le boulot : chacun prend le(s) sien(s) et s’en occupe… Je me suis farci celle pour « Sylvain », du coup voici la marche à suivre pour ceux qui se demandent comment faire la même.
L’élément Wikidata concernant votre prénom
On commence par l’élément concernant le prénom lui-même. Là, en général, c’est un beau bordel hérité de Wikipédia. D’abord, les prénoms connaissant généralement de légères variations d’une langue à l’autre, chaque langue a en général fait un article titré avec la variante principale du prénom dans ladite langue (ex: Sylvain sur fr:, Silvano sur it:, Szilvánusz sur hu:), et l’a lié avec la forme principale dans une autre langue. Ce n’est pas terrible, notamment parce que en: par exemple peut avoir plusieurs articles sur des variantes du même prénom avec une interwification approximative, et ce qui n’arrange pas les choses, c’est qu’une même langue a parfois a plusieurs variantes assez différentes du même prénom (typiquement sur fr:, on a Stéphane et Étienne) et donc là aussi plusieurs articles. Je passe sur le fait que les articles sont parfois des articles détaillés sur le prénom, parfois des pages d’homonymie et parfois un mélange des deux.
La bonne solution pour régler ça, c’est de créer une entrée Wikidata par variante du prénom, d’y redispatcher les interwikis correctement, et de les relier les unes aux autres via la propriété réputé identique à (p460) (ce qui prend un peu de temps.) Les autres propriétés à ajouter sont :
- nature de l’élément (p31) avec pour valeur prénom féminin (q11879590), prénom masculin (q12308941) ou prénom épicène (q3409032)
- langue (p407) avec la ou les langues utilisant cette variante du prénom
Une autre possibilité est qu’il n’y ait pas du tout d’entrée pour le prénom en question, sur aucune Wikipédia, et donc pas non plus sur Wikidata (par exemple, c’est une variante féminine rare d’un prénom masculin, comme Sylvaine, ou l’inverse.) Il suffit alors de la créer sur Wikidata.
Les éléments des personnes portant ce prénom
Il suffit de trouver toutes les personnes portant le prénom en question (la bonne variante du moins) et leur ajouter la propriété prénom (P735) avec la valeur appropriée. Facile à dire, mais pour peu que le prénom soit courant, ça peut rapidement concerner des centaines, voire des milliers d’entrées.
Du coup, on va s’aider d’un outil de Magnus Manske : AutoList2. Il va nous permettre, d’une part de retrouver et lister toutes les personnes dont le label ou un alias commence par le prénom qu’on cherche, mais n’ayant pas cette déclaration de renseignée ; et d’autre part d’ajouter ladite déclaration. Compliqué ? Avec une capture ça sera peut-être plus clair…
Capture d’écran du logiciel AutoList2
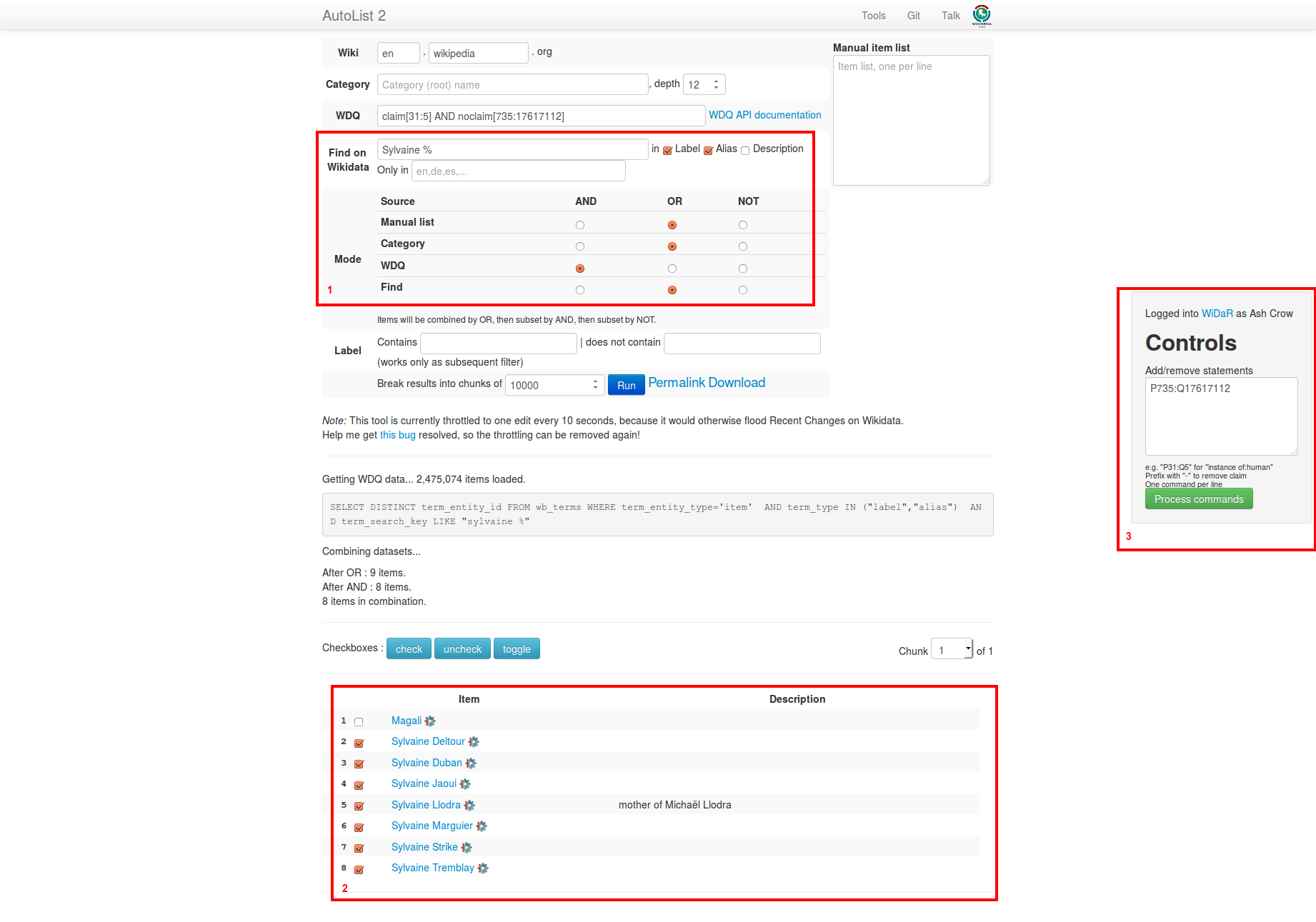
J’ai fait la recherche pour Sylvaine[1] et encadré 3 zones.
En 1, la recherche. On cherche donc toutes les entrées qui commencent par « Sylvaine », ce qui se traduit par « Sylvaine % » dans le champ « Find on
Wikidata » , qui ont pour « nature de l’élément (P31) → être humain (Q5) » et qui n’ont pas déjà la relation « prénom (P735) → Sylvaine (Q17617112) » comme on le voit dans le champ « WDQ » : « claim[31:5] AND noclaim[735:17617112] » (Vous noterez qu’il ne faut ici pas indiquer les P et Q des identifiants de propriétés et de valeurs.)
Dans « Mode », Find doit être sur OR (pour être exécuté d’abord) et WDQ sur AND. Les deux autres sources étant inutilisés, leur mode importe peu. Si on met les deux sources utilisées sur AND, AutoList2 ne sait pas par où commencer et ne retourne rien, si on met les deux sur OR, on recherche tout ce qui commence par Sylvaine ou qui est un être humain n’ayant pas la relation « prénom → Sylvaine », ce qui n’est pas ce qu’on cherche…
En 2, les résultats. Il y en a peu ici et j’aurais pu faire la modif à la main sur Wikidata, mais c’est pour l’exemple. On notera que le premier résultat est « Magali » : c’est une femme de lettres et Sylvaine est un des noms de plume qu’elle a utilisé.
En 3, la mise à jour. C’est ici qu’on va faire l’ajout de la propriété manquante. On ajoute donc « P735:Q17617112 » dans la case (cette fois il faut bien les P et les Q…), on décoche les résultats non pertinents de la liste des résultats (ici, on décoche Magali) et on clique sur « Process Commands » (il faut avoir autorisé l’utilisation de l’outil avec notre compte avant en cliquant sur le lien « WiDaR not authorised. ») À raison d’une modif toutes les dix secondes, ça peut prendre un peu de temps et si on voit qu’on a fait une connerie, on peut tout arrêter avec le gros bouton rouge « EMERGENCY STOP ».
Au final, on obtient ça :
Et le nom de famille ?
Pour le nom de famille, c’est pareil sauf qu’il n’y a normalement pas les variantes à démêler. L’entrée concernant un nom de famille doit avoir les relations suivantes :
- nature de l’élément (p31) → nom de famille (q101352)
- sous-classe de (p279) → nom de famille (q101352)
On peut aussi utiliser nommé en référence à (p138) si on connaît l’origine du nom.
Le truc pénible, par contre, c’est qu’Autolist risque de ne pas marcher pour retrouver les porteurs du nom : une requête commençant par « % » (par exemple « % Lefebvre ») est beaucoup plus gourmande et MySQL ne va pas aimer. Il est toutefois possible de ruser en utilisant la première lettre du prénom pour filtrer (en cherchant avec « A% Lefebvre », puis avec « B% Levebvre », etc.) mais ça découpe la requête et oblige à la faire plusieurs fois (jusqu’à 26, même si je doute que des prénoms commençant par toutes les lettres soient concernés. Ça peut se vérifier avec la recherche interne de Wikidata.)
Pour ce qui me concerne, ça donne ça.
Et maintenant, au boulot ! 🙂
Image d’en-tête:
Pas de bol…, par Ludovic sur Flickr (CC-BY-SA 2009)
